CKI architecture
In a nutshell, the CKI setup consists of the following components:
- the GitLab pipeline and connected testing lab
- the DataWarehouse GUI for result visualization and triaging
- various micro services that mediate the dataflow around them
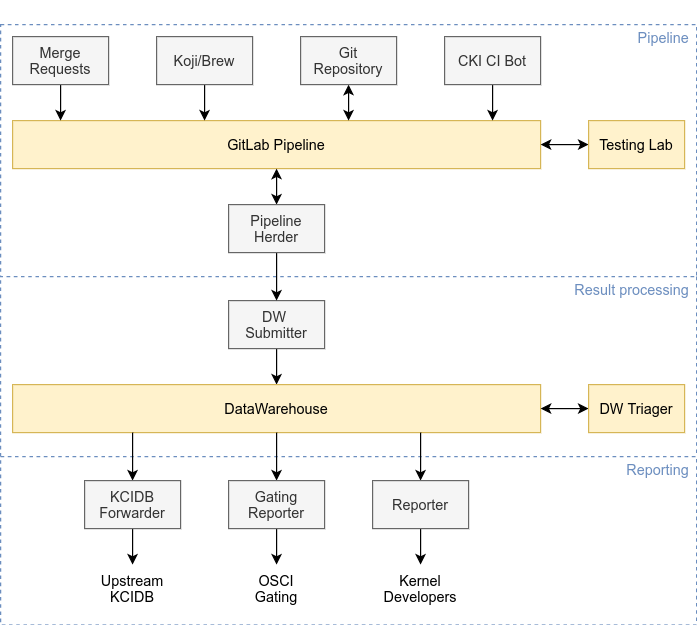
The following sections describe the various parts in more detail.
Pipeline
Triggering from merge requests
For merge requests on gitlab.com, the CKI pipeline is triggered as a multi-project downstream pipeline.
An example what this looks like in practice can be seen in the .gitlab-ci.yml
file in the CentOS Stream 9 kernel repository. With the templates
for the trigger jobs as defined in the kernel_templates.yml file in the
pipeline-definition repository, the trigger jobs eventually
boil down to something like
c9s_merge_request:
trigger:
project: redhat/red-hat-ci-tools/kernel/cki-internal-pipelines/cki-trusted-contributors
branch: c9s
strategy: depend
variables:
...
Triggering from Koji/Brew
Official Fedora, CentOS Stream and RHEL kernels are built using the Koji RPM building and tracking system.
When new kernel RPMs have been built, CKI testing is triggered via the
koji_trigger module in the cki-tools repository.
Triggering from git repositories
For Git repositories, e.g. on git.kernel.org, CKI testing can be triggered
whenever the HEAD commit of a branch changes. This is implemented via a regular
cron job calling into the gitrepo_trigger module in the cki-tools
repository.
Triggering via the CKI CI Bot
To test CKI code changes before they are deployed to production, the
gitlab_ci_bot module in the cki-tools repository allows to trigger
canary pipelines with the new code from a merge request. The bot
is implemented as a cron job and is present in all CKI projects that are used
in the GitLab pipeline. As the canary pipelines running new code are based on
previously successful pipelines, they are expected to complete successfully as
well.
GitLab pipeline
The GitLab pipelines run in the various branches of the CKI pipeline
projects. The actual pipeline code comes from the
pipeline-definition repository and is included via the
.gitlab-ci.yml file in the pipeline projects like
include:
- project: cki-project/pipeline-definition
ref: production
file: cki_pipeline.yml
Based on the specific trigger variables of the triggered pipelines, the jobs are configured appropriately for the kernel code under test.
Testing lab
The actual testing of the kernels happens outside the GitLab pipeline in a Beaker lab. The kpet-db repository hosts the database with the information to select the tests that should be run. The GitLab pipeline waits for testing to finish before continuing.
Transient failure detection
For the GitLab pipeline, network hiccups or upstream server issues might result in transient job failures that are not connected to the code under test. Next to retrying network requests wherever possible, the pipeline-herder checks failed jobs for signs of known transient problems. In that case, the failed job is automatically restarted.
For successful jobs or failed jobs where no such problems could be detected, the pipeline-herder hands the results to the next stage.
Result processing
Result submission
Results are prepared in GitLab pipeline jobs in KCIDB format.
Each job tries to submit their partial result to DataWarehouse via REST
API in the after-script section. In case of exceptions, the pipeline will
continue gracefully just logging them to Sentry for future
investigation by the team.
Once the pipeline passes pipeline-herder, either successfully or reaching an
unrecoverable state, it will send a message to datawarehouse-submitter,
which will then submit these final results to DataWarehouse.
DataWarehouse result visualization and triage
The DataWarehouse provides access to all CKI testing results. Additionally, it allows to manage known issues, i.e. failures and errors that are tracked in an external issue tracker.
Automatic DataWarehouse result triaging
Known issues that result in specific error messages in the log files can also be automatically tagged based on regular expressions. The datawarehouse-triager is responsible for the tagging of new results and the updating of old ones should the regular expressions change.
The triager is triggered in 3 occasions:
- In the last stage of the pipeline, once for each build variant. This is the only occasion for CVE pipelines. If an exception occurs at this point, it should fail gracefully to be later recovered by the following executions;
- Triggered by objects being created or updated in DW which is a consequence of “Result submission”, i.e. job finishes (direct API call) and later when the whole pipeline finishes (via MQ through pipeline-herder, then datawarehouse-submitter hits DataWarehouse API).
- Whenever a Quality Engineer updates an issue regex in DataWarehouse, as long as the results were created and submitted to DW within the last two weeks.
Reporting
Continuously, the kcidb-forwarder takes care of forwarding incoming KCIDB results to the upstream KernelCI project. The reporter is responsible for sending email reports, mostly to upstream mailing lists.